
国立国会図書館のサービスで蔵書の一部をPDFのデジタルデータで閲覧することができます。
絶版本など手に入らない書籍を無料で読むことができるおトクな方法です。
人気の絶版本は中古価格も高騰しており、なかなか閲覧することができませんでした。国会図書館サーチを活用することで費用かけずに閲覧することができます。
国立国会図書館サーチとは
国立国会図書館サーチとは、国立国会図書館の所蔵資料やデジタル資料を検索したり、閲覧やコピーを申し込んだり、様々なサービスが利用できます。
利用方法
1. 会員登録する
国立国会図書館の利用者登録を行います。会員登録にあたり本人確認書類が必要となります。
マイナンバーカードや運転免許証などの公的機関が発行した書類や、現住所が記載された学生証など、氏名、現住所、生年月日が証明できる書類が必要となります。

メールアドレスの登録

利用者登録と本人確認書類のアップロード
個人情報の入力と本人確認書類をアップロードします。

注意点としては、本人確認書類として運転免許証をアップロードする際は両面の画像のアップロードが必要となります。
私は表面しかアップロードしておらず申請のやり直しとなりました…。これから申請する方はご注意ください。

本登録まで待つ
本人確認作業には、通常5開館日程度かかるとの記載があります。
国会図書館の休館日は日曜日、国民の祝日・休日、年末年始、毎月第三水曜日とのことで、最速でも1週間ほどかかるようです。
(2025年7月現在)登録作業の遅延
登録作業が遅延しているようで、6/19に登録して7/17に返信がありました。(1ヶ月近くかかるようです)
先述の通り運転免許証の裏面のアップロード忘れだったため再度登録が必要になり、実際に使い始めるのは8月下旬以降になりそうです。
2. データを閲覧する
国会図書館サーチのトップページから書籍名を検索することで候補が表示されます。

「インターネットで読める」の表示があるものが対象となります。
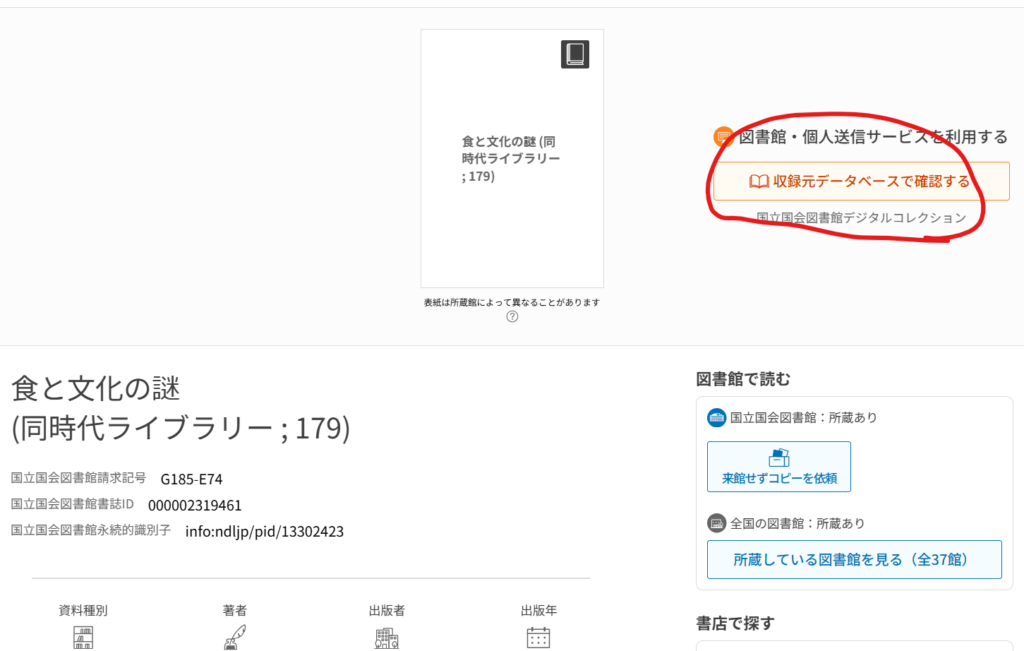
「収録元データベースで確認する」をクリック
3. データをPDFに出力する
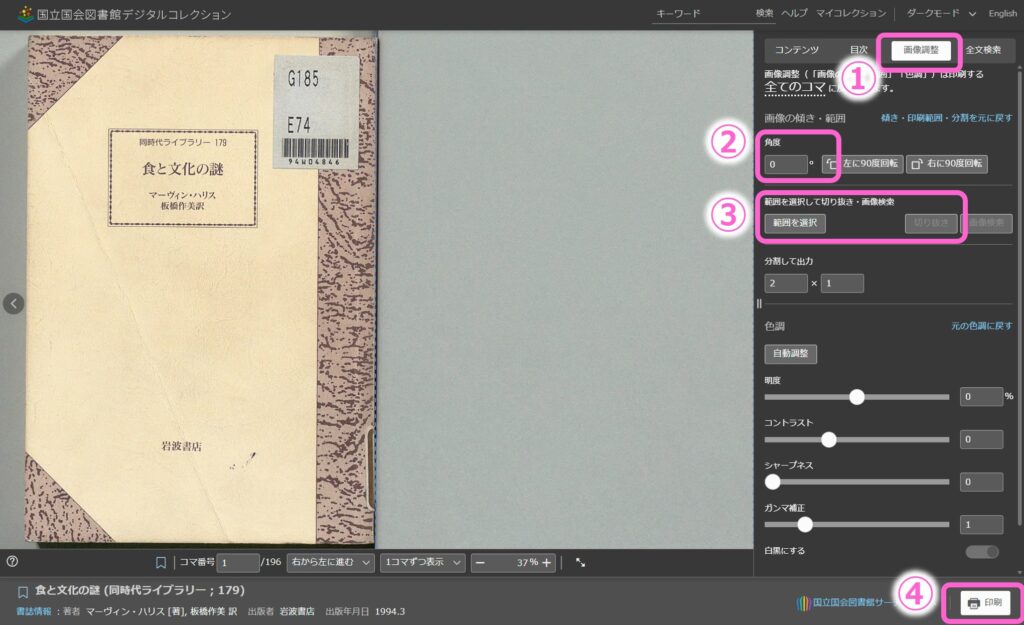
①ビューワーの画像調整をクリックするとツールが開きます。
②書籍のスキャン時に水平になるように調整されていますがズレているものもあり、気になれば角度を調整しましょう。角度はプラスマイナス/小数で指定することができます(1°回転させるだけでも大きく変化します)
③PDF化する対象範囲を絞り込みます。元画像は書籍よりも少し広めに撮影されているので、必要な個所のみトリミングすることでPDF化した後に読みやすくなります。
※画像には利用者IDなどの印字が入るため、ページ下部は少し広めに空けておいた方が良いです。
④「印刷」をクリック。こちらは通常の紙への印刷ではなく「出力」といった方がわかりやすいかもしれません。
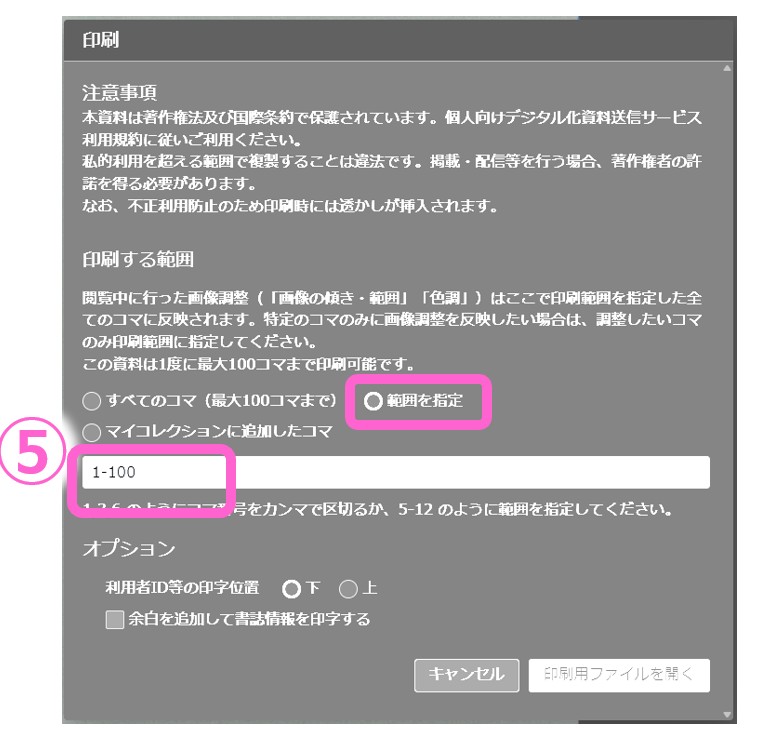
⑤印刷範囲(ページ数)を選択します最大100コマ(枚)分をPDF化することができます。
出力したPDFファイルには「ファイルの出力日時秒、ID、名前」が刻印されます。
4. PDFを結合する
100コマまでのファイルは一度に出力することができますが、複数ファイル存在する場合はPDFファイルを結合した方が便利です。
①chromeでPDFファイルを開き、「ctrl + P」で印刷設定を開き、「PDFで保存」を選択する。
※出力されたそのままのファイルは閲覧できますが編集ロックがかかっており、PDFファイルの結合ができません。
②Pythonでファイルを結合する
インプットフォルダとアウトプットフォルダを作成し、下記のコードで複数のPDFファイルを1つに結合します。
import os
from pypdf import PdfReader, PdfWriter
# 結合対象のPDFファイルがあるフォルダ
input_folder = "./01_original_files"
output_folder = "./02_output_files"
# PDFファイル一覧を取得し、ファイル名でソート
pdf_files = sorted(
[f for f in os.listdir(input_folder) if f.lower().endswith(".pdf")]
)
# PdfWriterで結合処理
writer = PdfWriter()
for pdf_file in pdf_files:
pdf_path = os.path.join(input_folder, pdf_file)
reader = PdfReader(pdf_path)
for page in reader.pages:
writer.add_page(page)
# 出力ファイルパス
output_path = os.path.join(output_folder, "merged_output" + pdf_files[0])
with open(output_path, "wb") as f_out:
writer.write(f_out)
print(f"結合完了: {output_path}")
結合したファイルをお好みのPDFビュワーなどで閲覧することができます。
PDF書籍のビューワーとしては紀伊国屋書店の「Kinoppy」が操作性が高くておススメです。
さいごに
以上の手順で国会図書館にて保有している書籍をPDF化して閲覧することができます。
国会図書館の利用規約に則り、ルールを守って適正な範囲で楽しむようにしましょう。
※個人利用の範囲ではOKですが、不特定多数に流通させたりすることはNGです。









